Abstract
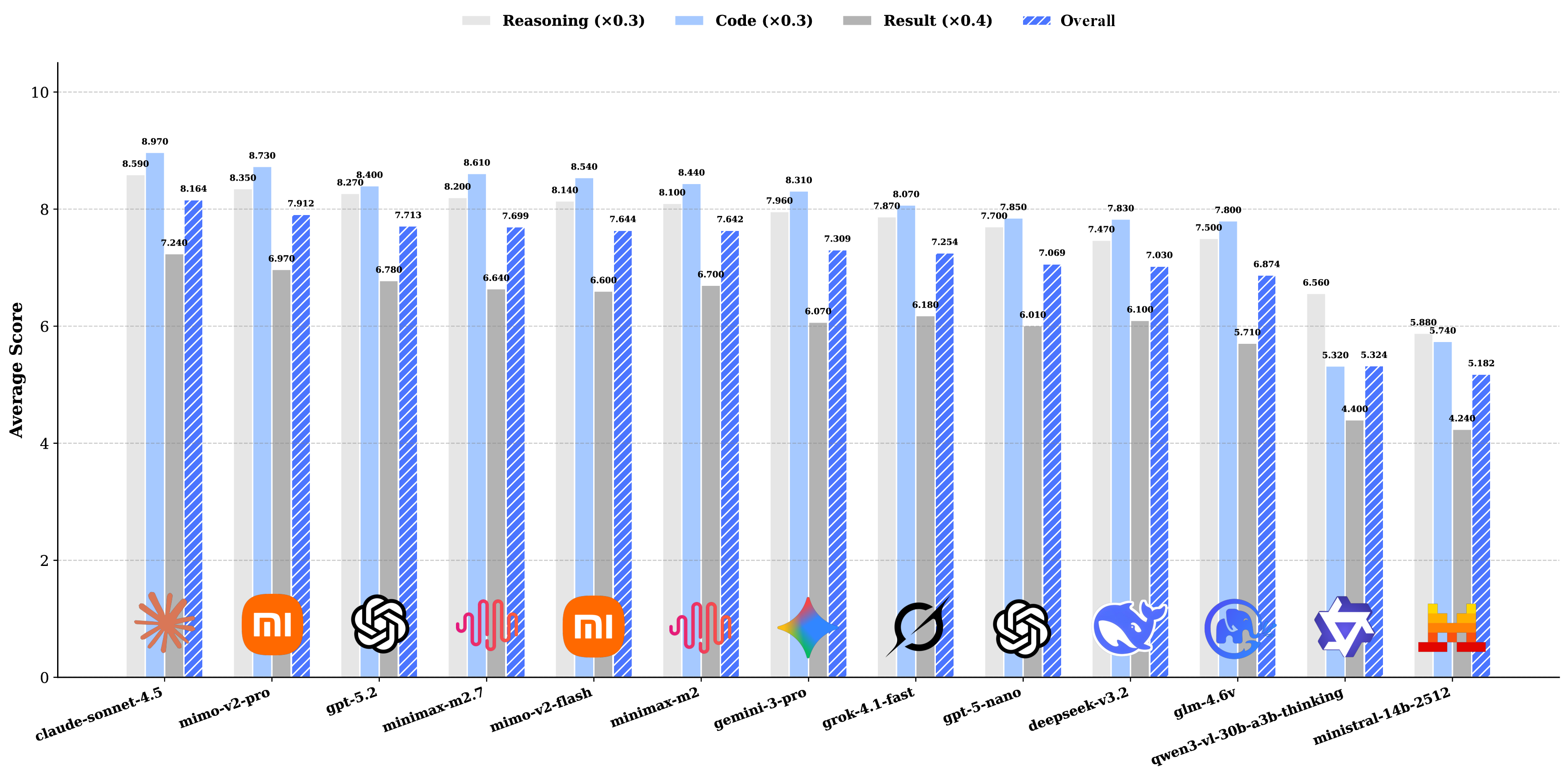
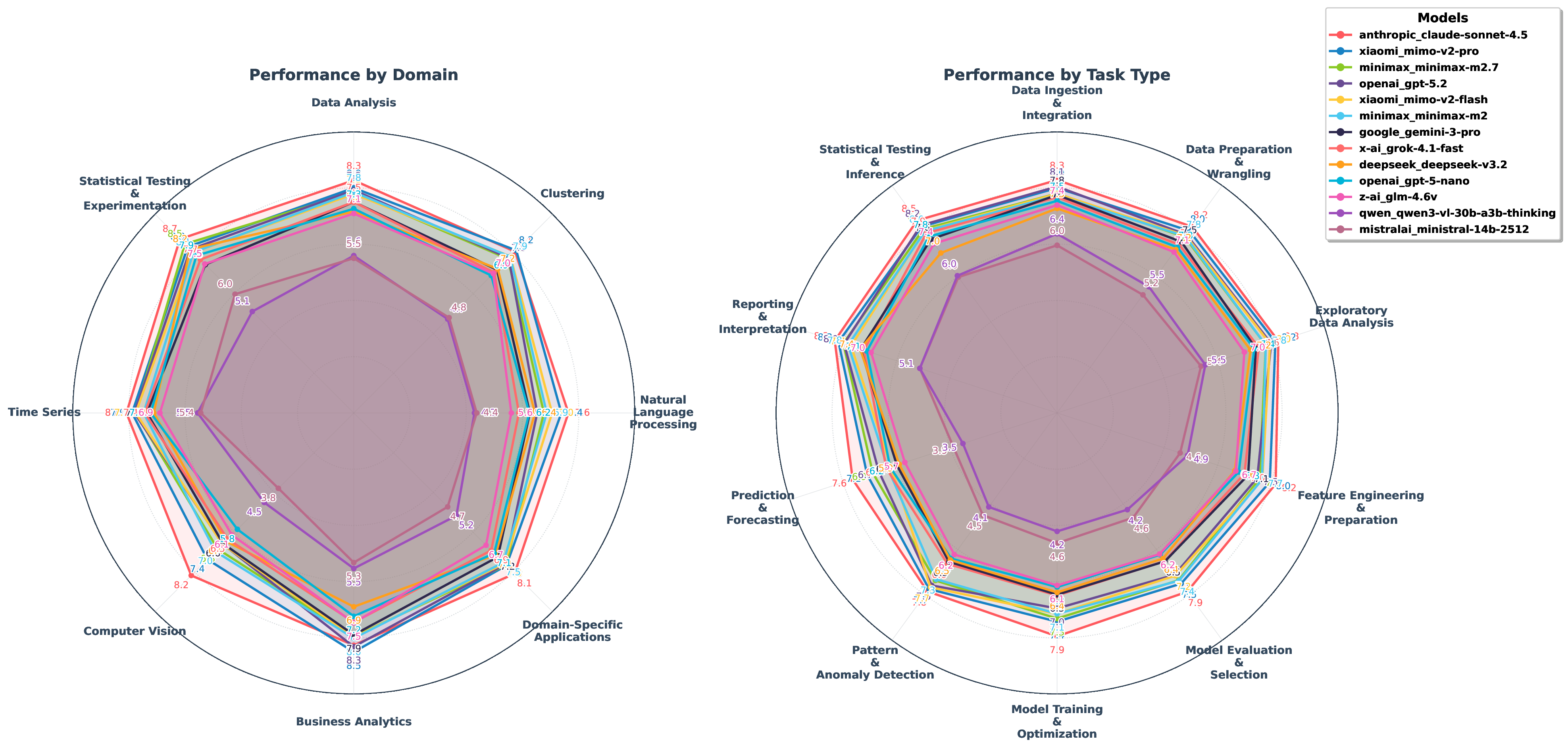
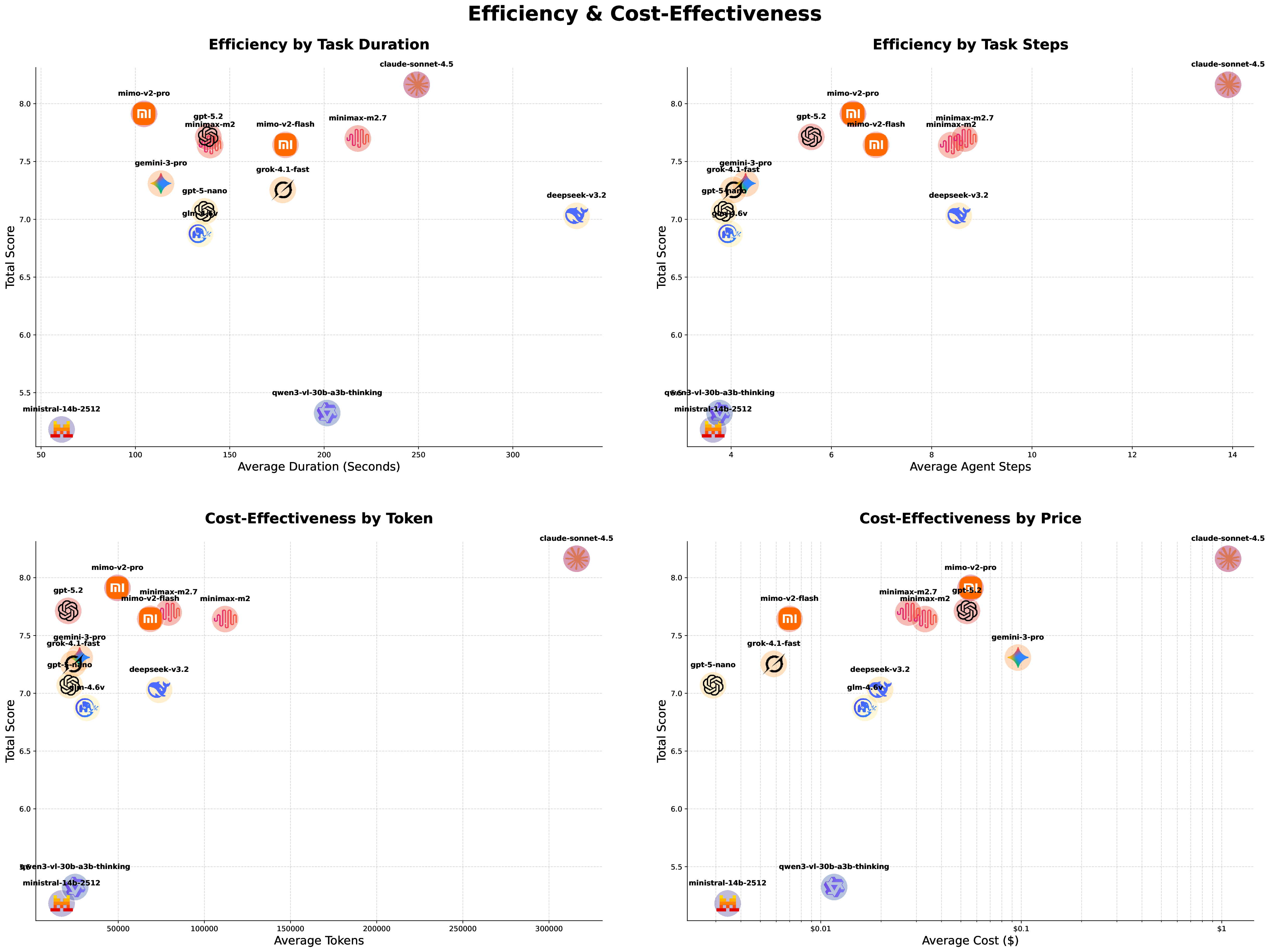
Recent LLM-based data agents aim to automate data science tasks ranging from data analysis to deep learning. However, the open-ended nature of real-world data science problems, which often span multiple taxonomies and lack standard answers, poses a significant challenge for evaluation. To address this issue, we introduce DSAEval, a benchmark consisting of 641 real-world data science problems grounded in 285 diverse datasets, covering both structured and unstructured modalities such as images and text. DSAEval includes three key features: (1) Multi-modal Environment Perception, enabling agents to interpret observations from both textual and visual modalities; (2) Multi-Query Interactions, reflecting the iterative and cumulative workflow of real-world data science projects; and (3) Multi-Dimensional Evaluation, providing comprehensive assessment across reasoning processes, code generation, and final analytical results. We systematically evaluate 13 advanced agentic LLMs on DSAEval. Experimental results show that Claude-Sonnet-4.5 achieves the strongest overall performance, while MiMo-V2-Pro and GPT-5.2 demonstrate the highest efficiency in execution duration and reasoning steps, respectively. In addition, MiMo-V2-Flash emerges as the most cost-effective model. We further show that multimodal perception consistently enhances performance on vision-related tasks, with improvements ranging from 2.04% to 11.30%. Overall, although current data science agents perform strongly on structured data and routine analytical workflows, substantial challenges remain in unstructured domains. Finally, we discuss critical insights and outline future research directions for autonomous data science agents.